LLM Integrations

LLM-Agnostic by Design
Hyperdrome is not locked into a single AI provider. The agent architecture separates intent parsing, context gathering, and execution into independent layers — so the LLM backend can be swapped without changing anything else. This means Hyperdrome works with any large language model today, and will work with any model released tomorrow.Supported Models

Claude
Opus, Sonnet, Haiku — Live

GPT-4
GPT-4o, GPT-4, GPT-4 Turbo — Live

Gemini
Gemini 2.5 Pro, 2.5 Flash — Live

Open Source
Llama, Mistral, Qwen, DeepSeek — Planned
Architecture
The agent pipeline is model-agnostic at every stage: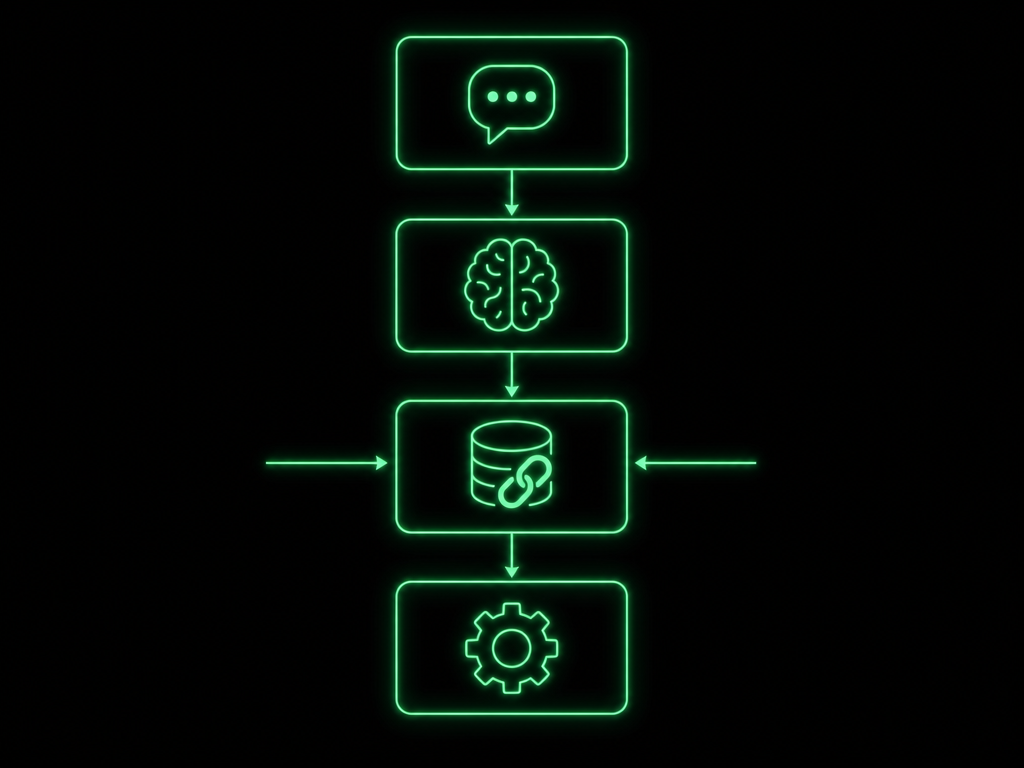
| Step | Component | LLM Required? | Description |
|---|---|---|---|
| 1 | Intent Parser | Yes — any LLM | Analyzes the user’s message to determine intent (swap, LP, vote, etc.) |
| 2 | Context Gatherer | No | Reads on-chain state + off-chain data (wallet, pools, prices, APRs) |
| 3 | Responder | Yes — any LLM | Generates natural language explanation with rich UI cards |
| 4 | Executor | No | Builds and submits the transaction on-chain |
Intelligent Routing
The backend automatically selects the best model for each request based on:| Factor | Logic |
|---|---|
| Complexity | Simple queries (price checks, balance) → fastest model. Complex multi-step actions → most capable model. |
| Language | Some models perform better in specific languages. The router optimizes for the user’s detected language. |
| Latency | If the primary model is slow or unavailable, the router falls back to the next best option in < 500ms. |
| Cost | The router balances capability vs. cost to keep inference free for all users. |
Bring Your Own LLM (Coming Soon)
Users will be able to connect their own LLM provider:- API key — Plug in your own OpenAI, Anthropic, Google, or any OpenAI-compatible API key
- Self-hosted models — Point the agent to your own Ollama, vLLM, or TGI endpoint running Llama, Mistral, Qwen, or any open-source model
- Custom system prompts — Tailor the agent’s personality, risk tolerance, and response style
- Full privacy — When using your own model, no data passes through Hyperdrome’s inference servers
Compatible Endpoints
Any endpoint that implements the OpenAI Chat Completions API format will work:| Runtime | Example Models |
|---|---|
| Ollama | Llama 3.3, Mistral, Qwen 2.5, DeepSeek V3, Gemma |
| vLLM | Any HuggingFace model |
| TGI | Any HuggingFace model |
| Together AI | Llama, Mixtral, Qwen |
| Groq | Llama, Mixtral, Gemma |
| Fireworks | Llama, Mixtral, DeepSeek |
Why LLM-Agnostic Matters
- No vendor lock-in — If a provider raises prices, degrades quality, or adds restrictions, Hyperdrome switches seamlessly.
- Best model for the job — Different models excel at different tasks. Routing lets Hyperdrome use the best tool for each request.
- Future-proof — New models are released monthly. LLM-agnostic architecture means Hyperdrome adopts them immediately without rewrites.
- User sovereignty — With Bring Your Own LLM, users control their data and inference. No dependency on centralized AI providers.
- Censorship resistance — Open-source models can’t be shut down or restricted. Users running their own Llama or Mistral instance have full autonomy.